

Attention might be all you need, but do you need all of it?
In the age of prompt engineering, is there still room for model training and development, or shall we just bend our kneels to GPT and its lookalikes?
Large language models (LLMs) have become incredibly popular in recent years, with models like GPT generating human-like text. Under the hood, these models use different architectures optimized for different purposes.
Although the traditional Encoder-Decoder model (exemplified by Google’s BERT) is more complex than their Decoder-only counterparts, OpenAI’s GPT achieves exceptional performance following the later configuration. How come a less complex model is better than a more complex one? Further, given the incredible capacities of GPT, one might be tempted to use it even for the most basic NLP tasks, such as text classification and sentiment analysis. But should you do it?
In this article, we’ll see how the model architecture that introduced the basics of attention and transformers is used and how we can tear it apart to achieve better and more viable results for each particular use case.
Transformers and Encoder-Decoder Models
The encoder-decoder architecture contains two main components — an encoder and a decoder (duh). Encoder-decoder models are commonly used for sequence-to-sequence tasks like translation and summarization. The Transformer model, proposed in the famous paper “Attention Is All You Need” [1], is a specific instance of the Encoder-Decoder architecture that uses self-attention mechanisms to improve on the shortcomings of predecessor models like LSTMs and GRUs.
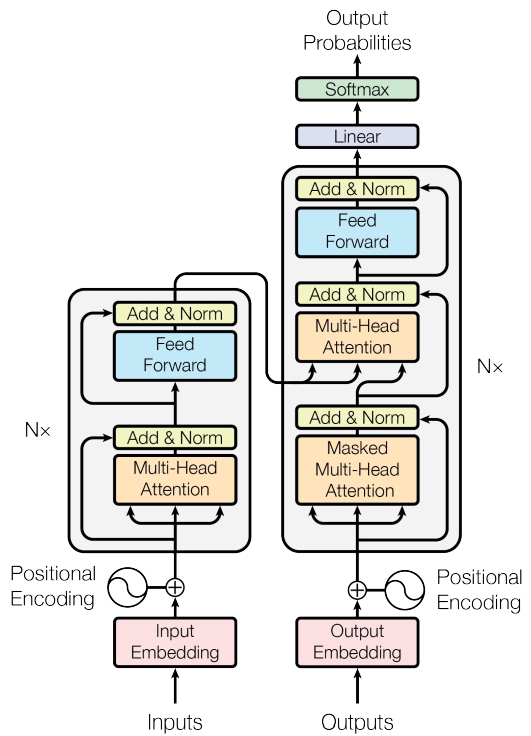
In the figure above, the Encoder is the block on the left side, and the Decoder is the block on the right. The Encoder takes in the input text and encodes it into a dense vector representation. We can think of this encoded representation as the semantic meaning and the context of the input. The Decoder then takes this representation and generates the output text token-by-token. That is why, in the figure, you can see Outputs being inputted into the Decoder: this represents the output tokens being inserted back at it, one by one. Naturally, the Decoder needs to know when to start and when to stop: those are represented by special tokens that define the start and the end of a text.
Encoder-Only Models
Encoder-only models contain only the encoder component. These models encode the input text into a semantic vector representation but do not generate any output text. Instead of connecting the encoder output to a decoder, its output is then connected to a head trained for one particular use case (normally not text generation).
Those models are useful for feature extraction from text. They are trained on tasks that do not require sequence-to-sequence mapping. The final output from the encoder can be used in various ways depending on the task — such as token classification, sequence classification, or even as features for other machine learning models.
One example of an encoder-only model is BERT [2]. It uses the encoder part of the original Transformer model to generate a fixed-size representation of an input text sequence, which can then be fine-tuned for various tasks such as text classification and named entity recognition. Because BERT only utilizes the encoder component, it is not inherently suited for sequence-to-sequence tasks out of the box, unlike the complete encoder-decoder Transformer architecture. Instead, BERT is generally used for tasks that require understanding the context of individual tokens in a text sequence.
Decoder-Only Models
Decoder-only models like GPT [3, 4] contain only the decoder part. The input to decoder-only models is a sequence of tokens that serve as the context for generating subsequent tokens.
While traditional Transformers (encoder-decoder) are trained for sequence-to-sequence tasks, decoder-only models are trained to predict the next token in a sequence given the preceding tokens. These models are typically auto-regressive, which means they generate output text token-by-token by conditioning the next token on previously generated tokens. This differs from the traditional encoder-decoder, where the encoder processes the entire input sequence at once, and the decoder generates the output sequence token-by-token.
Decoder-only models are generally used for tasks that require generating text or other types of data from some initial context. This includes text completion, text generation, and even tasks like image generation in the case of models like DALL-E [5].
Because they only include the decoder, these models may have fewer parameters than a full Transformer that includes both an encoder and a decoder. However, models like GPT-3 and GPT-4 have shown that decoder-only architectures can scale to a huge number of parameters.
Why not just use GPT for everything?
Well, you could. In most cases, GPT-like models can generate text with success and understand context without an encoder by its side. Further, we have been empirically convinced that those models can also perform tasks such as text classification and sentiment analysis with high accuracy: by providing GPT with a suitable prompt, its capabilities are almost endless. But as with all great things, it is not free. Far from it, actually.
The table below shows how BERT can achieve better results than GPT, particularly for those semantic and classification tasks (for more information on the dataset and benchmark used, refer to [6]). Keep in mind that this is a reference to the first version of GPT, not the latest one.
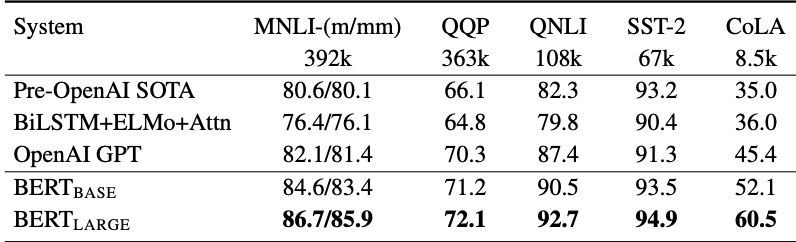
As Data Scientists, then, we shall make a choice. And the choice depends on the end application. Choosing an encoder-decoder solution only because it provides good accuracy might unnecessarily increase a project’s development time and cost. The same goes for selecting a decoder-only model like GPT: although it can classify texts or detect sentiments in sentences, it comes with the price of a gigantic model. For basic solutions such as text classification and sentiment analysis, encoder-only models can be a suitable in-house low-cost solution.
Summary
Regarding their inner workings:
- Encoders extract semantic meaning and context from text, outputting a representation of those.
- Decoders generate text from text by predicting which is the most probable next word, given a previous one.
When joining forces, an Encoder-Decoder model generates text by first extracting a semantic meaning and context from an input (using the Encoder) and then predicting words one by one using a combination of those meanings and the previous word just predicted (using the Decoder).
- Encoder-decoder models provide greater flexibility but are slower to train. Those are used for translation and summarization.
- Encoder-only models are efficient for classification and feature extraction but cannot generate text.
- Decoder-only models are fluent at text generation, like conversations.
References
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems. arXiv:1706.03762
[2] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805
[3] Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. OpenAI Technical Report
[4] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Technical Report
[5] Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., & Sutskever, I. (2021). DALL·E: Creating images from text. OpenAI Blog
[6] Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2018). GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. arXiv:1804.07461
